使用 BPE 原理进行汉语字词切分(重制版)
源码已发布到 Github:
pluveto/bpe_v3: 基于 BPE 实现的中文分词。优化:预处理,并行计算,多字词,多词表 (github.com)
目标
采用 BPE 算法对汉语进行子词切割,算法采用 Python (3.0 以上版本)编码实现,自行编制代码完成算法,不直接用 subword-nmt 等已有模块。
BPE 算法介绍
BPE 的概念源自一种无损压缩算法中提出。
BPE 压缩算法
举例 1 :对于 aaabdaaabac 的 BPE 压缩过程如下:
- 寻找出现频率最高的相邻两字符(BP,Byte Pair)
aaabdaaabac
aa|||||||||
aa||||||||
ab|||||||
bd||||||
da|||||
aa||||
aa|||
ab||
ba|
ac
统计如下:
aa - 4
ab - 2
ac - 1
bd - 1
da - 1
因此替换频率最高的 aa 为 [aa]:
[aa]abd[aa]abac
再次统计如下:
[aa]a - 2
ab - 2
bd - 1
d[aa] - 1
ba - 1
ac - 1
因此替换 [aa]a 为 [aaa]:
[aaa]bd[aaa]bac
重复。替换 [aaa]b 为 [aaab]:
[aaab]d[aaab]ac
此时不必再替换。数据被压缩成:
XdXac
其中 X 映射为 aaab
此时,只要一个压缩后的数据,加上一个字典,就能表示原数据。
BPE 分词思路
无论在英文还是中文里,词汇的特点就是出现频率高。
假设我们对这句话压缩,大概率会得到一个这样的结果:
压缩后文本
"W1在W2W3W4里,W5的W6W7W8W9高。"
哈希表:
W1 = [无论]
W2 = [英文]
W3 = [还是]
W4 = [中文]
W5 = [词汇]
W6 = [特点]
W7 = [就是]
W8 = [出现]
W9 = [频率]
也就是说,词汇的可以用是高频的相邻字符来代表。(当然,不一定是两个字符,比如汉语成语常常是连续的四字高频的字符)
这给了我们一种分词的思路。
BPE 算法设计
上面基本已经成型了,但我们还需要对有关数据结构进行建模。
假设有数据集如下:
所谓调度就是决定某时刻,应该运行哪个进程。
调度分为实时调度和非实时调度。
实时调度分为硬实时和软实时。
这个数据集有三行,假设指派给三个执行器。记作 E1,E2,E3。
E1 收到的数据是:所谓调度就是决定某时刻,应该运行哪个进程。 按照字符切分,得到:
所 谓 调 度 就 是 决 定 某 时 刻 , 应 该 运 行 哪 个 进 程 。
我们注意到空格标点符号容易造成干扰,因为最终词典不会有标点。不妨统一替换为 “#”。
所 谓 调 度 就 是 决 定 某 时 刻 # 应 该 运 行 哪 个 进 程 #
然后,就是进行高频组合的相邻连接。
统计高频的相邻字符
比如,我们发现 word[i]+word[i+1] = 所 谓 | 调 度 | 决 定 | 某 | 时 刻 | 运 行 | 进 程 的频次非常高,就可以合并为:
所谓 调度 就 是 决定 某 时刻 # 应 该 运行 哪 个 进程 #
多字词词汇生成
一般来说,我们需要进行多轮处理,进一步合并。因为很多次并不止两个字,例如 “某 时刻” 或许可以合并为 “某时刻”,“国家 主席 毛泽东” 可以合并为 “国家主席毛泽东”。
实现方法就是多轮处理。伪代码如下:
1round_num = 1 # 当前处理的是第几轮
2max_round_num = 4 # 最大轮数
3
4while round_num <= max_round_num:
5 logger.info("Round {} start...".format(round_num))
6 # 初始化
7 shared_freq_stat_map = {}
8 # 进行词典的建立
9 ParalledTask.create("--freq stat round={}".format(round_num))\
10 .set_nworker(self.nworker)\
11 .set_worker_args({'datasets': ds})\
12 .set_worker_func(_train_worker)\
13 .set_progress_goal(len(self._train_lines_np))\
14 .execute()
15 # 从高频到低频排序
16 sorted_freq_stat_ls = sorted(
17 shared_freq_stat_map.obj.items(), key=lambda x: x[1], reverse=True)
18 # 选出一些词汇纳入词汇表
19 sorted_freq_stat_ls = dict_filter(sorted_freq_stat_ls)
20 # 利用词汇表合并字节对
21 ParalledTask.create("--connect round={}".format(round_num))\
22 .set_nworker(self.nworker)\
23 .set_worker_args({'datasets': ds, 'thold': thold})\
24 .set_worker_func(_connect_worker)\
25 .set_progress_goal(len(self._train_lines_np))\
26 .execute()
27 # 进入下一轮
28 round_num += 1
其中,涉及到两个工作函数,一个负责 单行数据处理,生成词表,一个负责 连接词表命中词
单行数据的处理思路
1for line in line_strs:
2 # 对每个 Byte Pair 进行处理
3 for i in range(len(line) - 1):
4 # 如果是 `#`,则跳过
5 if line[i] == '#' or line[i+1] == '#':
6 continue
7 # 获取当前词和下一个词,如 '天安', '门'
8 cur_word: str = line[i]
9 next_word: str = line[i + 1]
10 # 当前词和下一个词拼接,如 '天安门'
11 cur_word_next_word: str = cur_word + next_word
12 # 当前词和下一个词拼接的词频
13 freq = inner_freq_stat_map[cur_word_next_word]
14 # 当前词和下一个词拼接的词频加1
15 inner_freq_stat_map[cur_word_next_word] = freq + 1
16 with bar.mutex:
17 bar.obj()
18# 将当前行的词频统计表加入总表
19with shared_freq_stat_map.mutex:
20 for key, value in inner_freq_stat_map.items():
21 shared_freq_stat_map.obj[key] += value
词汇连接的实现原理
bpe_cn.py 145:
1bar: WithMutex = ctx.get('bar')
2worker_id = ctx.get('worker_id')
3line_strs: List[List[str]] = ctx.get('datasets')[worker_id]
4thold = ctx.get('thold')
5for line in line_strs:
6 # 对每个 Byte Pair 进行处
7 i = 0
8 while(i < len(line) - 1):
9 # 如果是 `#`,则跳过
10 if line[i] == '#' or line[i+1] == '#':
11 i += 1
12 continue
13 # 获取当前词和下一个词,如 '天安', '门'
14 cur_word: str = line[i]
15 next_word: str = line[i + 1]
16 # 当前词和下一个词拼接,如 '天安门'
17 cur_word_next_word: str = cur_word + next_word
18 # 比较是否大于阈值
19 if shared_freq_stat_map.obj[cur_word_next_word] > thold:
20 # 如果大于阈值,则连接
21 line[i] = cur_word_next_word
22 # 删除下一个词
23 line.pop(i + 1)
24 i += 1
25 i += 1
26 with bar.mutex:
27 bar.obj()
最大匹配分词算法设计
这部分相对简单。查询词典中最长的词,与当前串比较即可。
算法预览
1 def tokenize(self, spaced_sentence: list) -> list:
2 """对句子分词"""
3 si = 0
4 result = []
5 while si < len(spaced_sentence):
6 matched = False
7 prevlen = 0
8 to_match = ''
9 for w, c in self.user_dict_items:
10 if prevlen != len(w):
11 to_match = ''.join(spaced_sentence[si:si + len(w)])
12 prevlen = len(w)
13 if w == to_match:
14 result.append(w)
15 si += len(w)
16 matched = True
17 break
18 if not matched:
19 result.append(spaced_sentence[si])
20 si += 1
21
22 return result
效果预览
测试数据:
他是一位声誉很高的学者,凭借丰富的知识储备,在这部重要的作品中,就弥源太是否皈依进行过讨论。
结果:
['他是', '一位', '声誉', '很高的', '学者', ',', '凭借', '丰富的', '知识', '储备', ',', '在这', '部', '重要的', '作品', '中', ',', '就', '弥', '源', '太', '是
否', '皈', '依', '进行过', '讨论', '。']
进一步优化
标点符号预处理
中英文标点一般来说不是词汇的组成部分。(除了 - 等特殊情况),因此可以将其替换为 # ,而在训练时,对 # 当作硬切分,即不成词。
1 puncs_zh = ['。', ',', '?', '!', ';', ':', '、', '(', ')', '「',
2 '」', '“', '”', '‘', '’', '《', '》', '【', '】', '…', '—', '~', ' ']
3 puncs_en = ['.', ',', '?', '!', ';', ':',
4 '(', ')', '"', '"', '\'', '\'', '<', '>', '[', ']', '...','~']
5 puncs = [*puncs_zh, *puncs_en]
6 # 替换标点符号为 `#`
7
8 def _replace_worker(ctx: dict):
9 task = ctx.get('task')
10 bar = ctx.get('bar')
11 worker_id = ctx.get('worker_id')
12 line_strs: List[List[str]] = ctx.get('datasets')[worker_id]
13 for line in line_strs:
14 for i in range(len(line)):
15 if line[i] in puncs:
16 line[i] = '#'
17 with bar.mutex:
18 bar.obj()
数据集去重
我们发现训练集有很多是重复的,会造成过拟合,即把一些生僻的字节对当成高频词处理。解决方法非常简单:
self._train_lines_np = np.unique(self._train_lines_np)
并行计算优化
详见另一篇文章“Python 实现简单的多线程 MapReduce 计算框架”
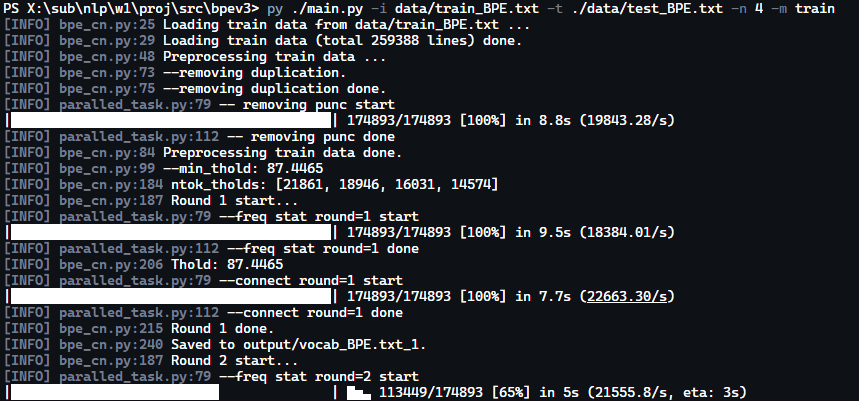
二字词与三字词的取舍
我们试验发现,有时候虽然产生了三字词,但实际上其子二字词的词频远远更高。举个例子,“写代码” 与 “代码”,后者的频率更高,因此将后者纳入词表是更恰当的。
因此对于前面的词,就可以舍掉:
1# 比较是否大于阈值
2if shared_freq_stat_map.obj[cur_word_next_word] > thold:
3 if shared_freq_stat_map.obj[cur_word] / shared_freq_stat_map.obj[cur_word_next_word]\
4 > ratio:
5 i += 1
6 continue
7 # 如果大于阈值,则连接
8 line[i] = cur_word_next_word
9 # 删除下一个词
10 line.pop(i + 1)
11 i += 1
建词 Baseline 与阈值动态调整
我们不断迭代生成更长的词的过程中,如果最重要生成 10000 词,则前几轮迭代实际上必须采用更多的词。
同时,我们希望有一个最低阈值,如果频率还低于这个阈值,就应该放弃。
1baseline = int(nline / 12)
2ntok_tholds = [int(baseline*1.5), int(baseline*1.3),
3 int(baseline*1.1), baseline]
4while in_round:
5 ntok_thold = ntok_tholds[round_num - 1][-1][1]
6 thold = max(min_thold, thold)
7 logger.info("Thold: {}".format(thold))
建立多级词表
我们实际上会发现,有时候有必要按多种标准进行划分。例如“全面深化改革”实际上是一个专有名词,应该划为一词。同时,当上下文为:全面xxx时,“全面”一词也应该被划出。所以我们生成多词表,然后用前面的 MMT 算法进行分词:
max_match_token.py
1def main():
2 print(
3 Tokenizer()
4 .add_dict(load_word_freq_map("output/vocab_BPE.txt_1"))
5 .add_dict(load_word_freq_map("output/vocab_BPE.txt_2"))
6 .add_dict(load_word_freq_map("output/vocab_BPE.txt_3"))
7 .add_dict(load_word_freq_map("output/vocab_BPE.txt_4"))
8 .tokenize(list("他是一位声誉很高的学者,凭借丰富的知识储备,在这部重要的作品中,就弥源太是否皈依进行过讨论。"))
9 )