Raft 共识协议通俗解释——数据流视角
私以为,Raft 协议并非难在本身,而难在理解它在解决什么问题。
背景知识
集群和日志
一个集群之所以为集群,是因为其单节点性能不足以提供服务。而集群整体对外暴露的主要功能,同单体服务没有区别。
简单起见,我们抽象为两种操作:读和写。

每次操作称为一个日志。理论上,在初态经过所有日志造成的状态转移的变换之和,将得到最终状态的集群。
例如集群提供了一个分布式配置文件功能。此配置文件的初态是:
weather: rain
day: 2022-5-5
而日志是:(R/W 表示读写)
R weather
R day
W day 2022-5-6
W weather sleet
R day
W day 2022-5-7
W weather hail
那么,集群的现态为:
weather: hail
day: 2022-5-7
这是对**“日志式”系统**的一种简单理解。
怎么知道谁是 Master?
当客户端的目标是多主机时:我们假设客户端知道所有集群结点的地址。那么,第一个摆在面前的问题是:我怎么知道应该连接哪个结点?
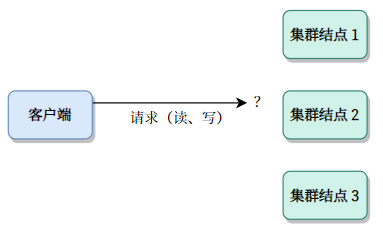
首先,我们考虑一种简单情况,所有客户端都只允许与其中一个结点通信。称为“主结点(Master or Leader)”,这样的好处是一切日志都是从主结点向从结点传播。
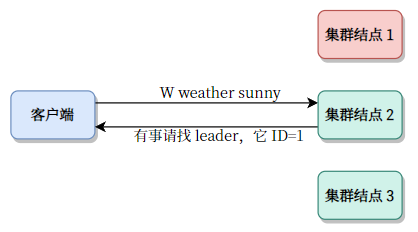
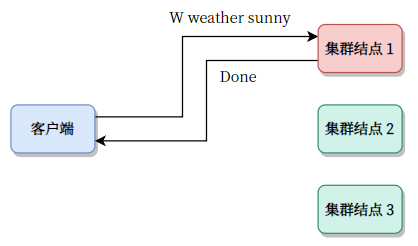
其次,我们可以考虑这样设计:客户端连接任意一个结点(只要有地址就行,假定地址已经是客户端的已知信息)。
然后如果结点自己就是主节点,则正常操作。否则会告诉客户端,我不是主节点,谁谁谁谁才是主节点。这样的操作称为重定向。
我们用红色表示主节点。
集群怎么就状态一致了?
前面我们说,集群先是处于初态,然后经过一系列日志(状态转移),就变成现态。
但其实集群内个结点之间通信是有延迟的,同时有天灾人祸等出错的可能性,状态转移的先后顺序、成功与否都会导致最终状态不一致。
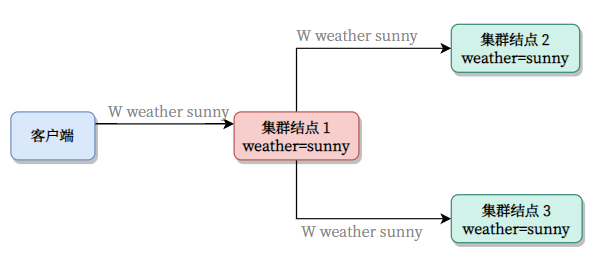
要确保集群状态一致,就是本文 Raft 的重点。我们将以一个 W weather sunny(将天气更改为 sunny)的日志为例,解释 Raft 协议的工作原理。
Raft
理想状态(这不是 Raft)
客户端发出 W weather sunny 到 Master 之后,Master 首先更改自己的状态。然后请求更改 Followers 状态:
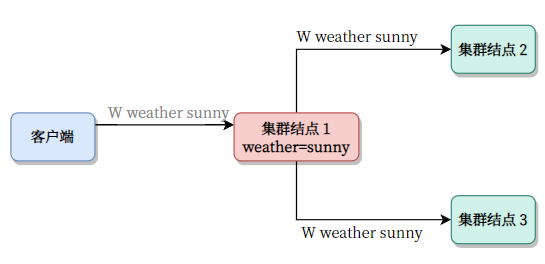
顺利的话是这样的:
两阶段提交
然而,这种理想情况在时间长河面前几乎是不可能事件。
比如说,主节点写成功了,但两个从节点都失败了,这怎么办?
你可能会说,那主节点先别写入磁盘。等从节点都成功了,再写入磁盘。
- 那万一有一个结点它就是挂了呢?岂不是要无休止等下去?
你又会说:那就别等全部了,那太苛刻了,超过一半成功,我(主节点)就当成功。
诶,恭喜你重新发明了两阶段提交。
(我们用粗体表示落盘,即持久化到磁盘等介质)
-
主节点收到请求后,先不着急落盘。(这称作预提交)
-
结点 3 收到了,并落盘。(下面 3 的
weather=sunny变成了粗体)
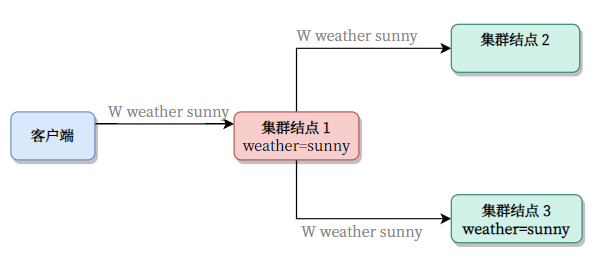
- 结点 1 一看,1/2 的子节点已经和我对上了。所以我也落盘。而 2 还处于懵逼状态。
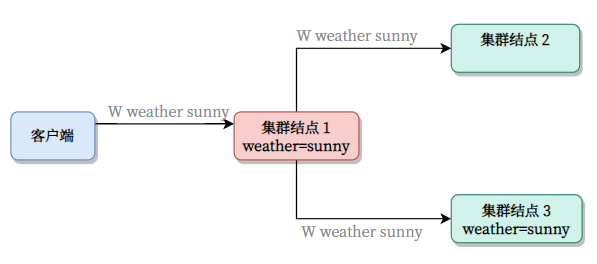
客户端因为主节点响应,所以认为 OK 了。
失败结点的重同步
那么问题又来了:
- 万一结点 2 又恢复了,我怎么保障它和主节点一致?
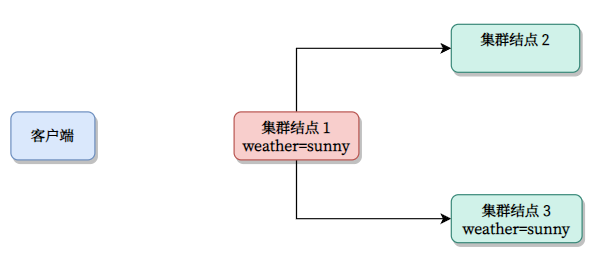
其实这不是啥大问题。各结点的状态对于主节点是已知的,因此,只要主节点单独给 3 开个小灶,帮他补习补习就可以了。
- 当结点掉线并丢失一段日志时,主节点会尝试向其补足日志。
轮询 vs 事件
这只是一种实现思路,你也可以让结点 2 自己主动要求拉取补足的数据,然后主节点再发送补全。学习还是得靠自己!
心跳机制
等等,主节点怎么知道哪个结点掉线了?所以还需要引入一个心跳机制。
这很简单,主节点向所有从节点询问:你还活着吗?从节点在一定时间内回答:我还活着。那么就认为没有掉线,反之则掉线。
这个机制通过主节点心跳定时器 实现。
万一主节点挂了呢?——选举机制
拉票机制
实际上集群开机的时候就是这种状态——所有结点均为从节点。
每个从节点是地位等同的,因此都想选举。所以,从节点会以随机时长初始化一个 选举计时器。
-
当从节点知道主节点存在时(比如收到了心跳信号)则此计时器归零
-
否则,计时器时间到,从节点会变成候选模式。
-
候选模式下,会向其它所有结点提出拉票请求。
-
一旦票数过半,自己就变成主节点。
-
投票机制
规定:在一个定时周期内,从节点只能投票给最先来的一个人。如果自己竞选,就那么这一票给自己。
Corner Cases
万一有多人竞选呢?
一种极端情况是两个结点同时竞选。那么:
-
要么他们获得相同的投票
- 则两人都无法成为主节点。会重新竞选。
-
要么他们获得不同的投票
-
要么其中一人获得过半投票:则此人变成领导
-
要么无人获得过半投票,则会重新竞选
-
情况:一个 3 Nodes 系统。Node 1 和 Node 2 都超时,都想竞选。
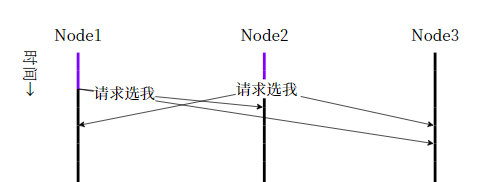
参考时间轴,
-
第一个收到投票请求的是 2。Node 1 希望 Node 2 投票。而 Node 2 已经投给自己,所以不会投给 Node 1.
-
然后 Node 1 和 Node 3 都收到 Node 2 的投票请求。而 Node 1 已经投给自己。因此 Node 3 和 Node 2 投给 Node 2.
-
Node 2 成为 Leader。
所以问题化解。
但如果:Node 2 成为 Leader 后的重置信号 Node 3 没收到呢?
脑裂情况
可以强制要求必须半数以上同意才能选上,避免出现一山二虎。
其它 Cases 补充中……
参考
这个链接 提供了可视化的 Raft 共识算法模拟。